超越限制:深入探索大语言模型的长度与上下文拓展技术
进阶位置编码、YaRN,注意力优化、超长上下文与高并发方案全解析
引言:长文本时代的LLM变革
随着大语言模型(LLM)能力的飞速发展,模型处理上下文长度的能力已成为突破瓶颈的核心议题。从最初的2k/4k token,到今天百k甚至百万token的上下文窗口,“长度”不仅考验模型结构的极限,更牵动了推理速度、硬件资源与应用场景的全局优化。本博客将系统梳理业界领先的长度与上下文扩展技术,深入进阶位置编码、YaRN、超长上下文建模、注意力机制优化与并发推理等前沿进展,为LLM开发者、研究员和企业提供权威解读和实用参考。
一、进阶位置编码与RoPE原理
位置编码是Transformer类模型捕捉序列顺序的关键环节。传统的正弦/余弦绝对位置编码存在外推能力有限、跨上下文泛化差等局限。近年来,旋转位置编码(RoPE,Rotary Position Embedding)通过将位置信息映射到复数域中的旋转操作,使相对位置关系自然融入attention矩阵,已成为Llama、Qwen、Baichuan等主流大模型基础。
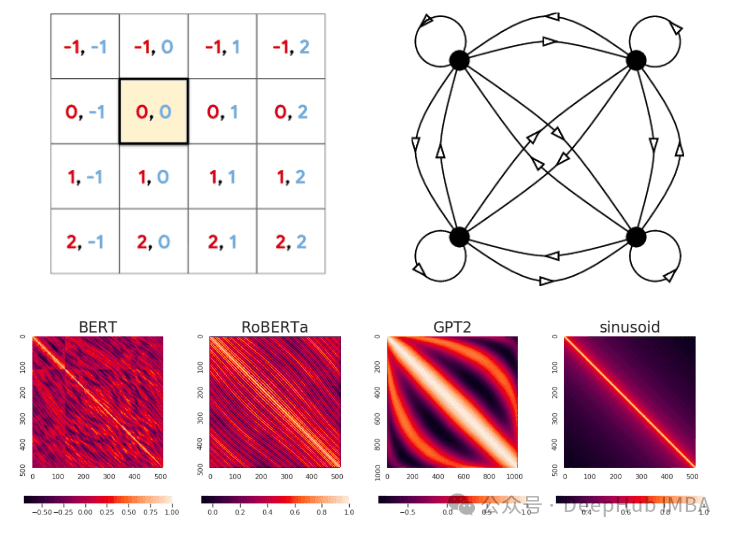
RoPE原理简述
RoPE将每个Token的高维embedding分组,分别用不同的频率进行二维旋转。其数学实质是将sin/cos嵌入转为复指数:
e^{ix} = cos(x) + i·sin(x),可解释为欧拉公式中的旋转。其优势在于:
1)相对位置信息内嵌,天然支持跨窗口迁移、长度扩展
2)计算高效,兼容现有attention优化
3)理论上支持超大上下文外推
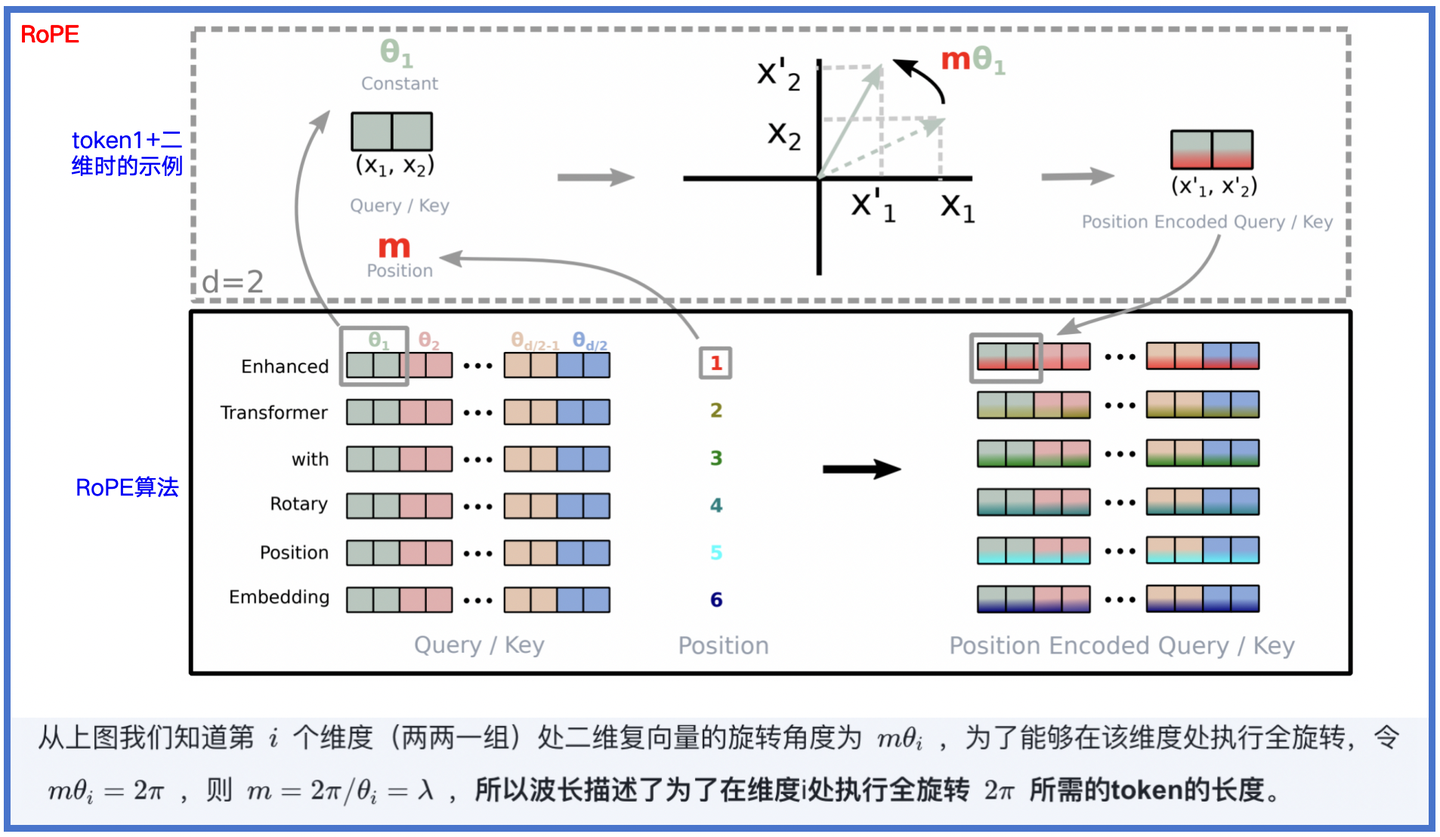
局限:RoPE 直接拉伸比例扩展context时,部分高频信息会损失,导致推理退化。因此,进一步技术如NTK-aware与YaRN等应运而生。
二、YaRN技术深度解读
YaRN(Yet another RoPE extensioN)是一种创新的RoPE位置编码扩展方案,实现了比基线RoPE/PI更高效的超长上下文推广能力。核心思路包括:
- 通过“分段拉伸(NTK-by-parts Interpolation)”仅对部分RoPE低频维度线性插值,高频维度保持不变,有效保留局部相对位置信息
- 结合动态温度缩放提升长距离Token的“可分性”,调控注意力分布收敛到更合理的层次
- 配合极少量超长文本微调,模型可直接有效“外推出100k+ Token”上下文

YaRN核心流程与优势
- 高频分辨保障:分段只“拉伸”低频RoPE维度,完整保留模型的局部语义定位能力
- 动态温度缩放:通过拟合长距离embeddings的注意力熵变化,动态调整温度以避免分布偏移
- 少量微调外推:实证表明,少于原始数据0.1%的长文本微调即可支持模型稳定“训练短,推理长”
| 方法 | 上下文容量 | 预训练数据比例 | 性能降级 | 优化复杂度 |
|---|---|---|---|---|
| RoPE比例扩展 | 16k-32k | ~100% | 易退化 | 低 |
| NTK-aware / PI | 32k-64k | 10-30% | 中 | 中 |
| YaRN | 100k+ | <1% | 微小 | 低 |
三、超长上下文处理与模型外推
针对 10万+token 超长文本,主流LLM体系采用“结构外推+高效微调”模式。方案演进如下:
- 直接拉伸:比例放大位置编码,但容易高频失真
- 分段插值:如PI/NTK/YaRN,仅插值部分频段,证明能大幅提升推理稳定性
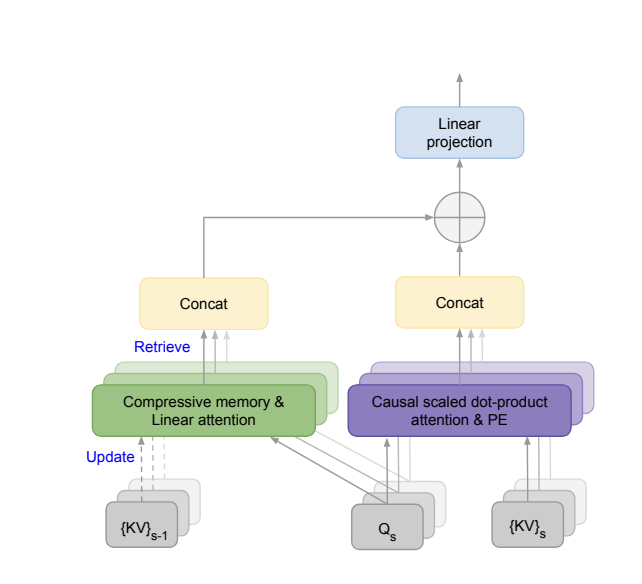
- 辅助链式记忆/压缩注意力:如Infini-attention,动态融合“本地”与“长程”context memory,实现理论无限token处理
案例:最新Kimi、GPT-4o等已支持100k甚至百万级上下文,均采用了NTK/YaRN/Infini-attention等创新机制与少量长文本微调。
四、注意力优化与推理效率提升
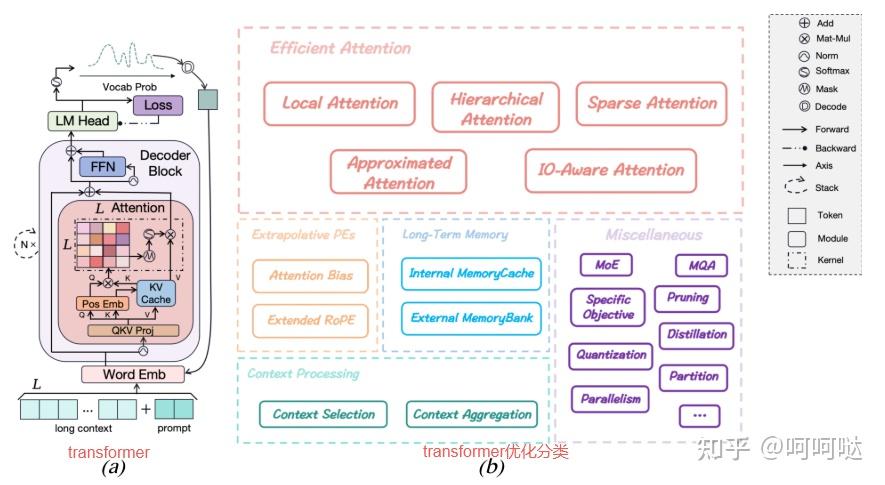
超长上下文代表着巨大的序列并行计算挑战,为此出现了多个高效注意力(Efficient Attention)研究方向,包括:
- FlashAttention / Linear Attention / Sparse Attention:通过稀疏存算、分块流式等策略降维并发
- Infini-Attention:关键KV值增量缓存+压缩,实现无限流context推理,见下图
- ALiBi、MoBA:加性偏移或块结构混合,提升极长距离token关联的建模能力
五、超并发推理与工程实践
随着超长上下文应用的兴起,高并发场景(如AIGC聊天、知识检索、批处理服务)的系统瓶颈同样成为关注核心。当前高效并发推理主流实现方法包括:
- vLLM/Continuous Batching:连续批处理与专门KV缓存管理,23倍吞吐提升
- 分层调度 / 动态资源分配:适配服务能力与业务压力弹性扩展
- 轻量框架(如lightllm、llama.cpp):高度并行+流式接口,轻松处理千级并发
- GPU高效推理:驱动模型适配分布式多GPU,优化显存占用

六、未来展望与总结
- 大模型“推理上下文长度”已从工程难题成长为创新快车道,未来将融合分布式、长程记忆、自适应注意力更多新架构
- 分段插值+微调策略如YaRN、NTK-by-parts或将成为10万Token级模型的基础设施
- 高效注意力与并发推理的工程创新仍是开放赛道,关注社区(vLLM、FlashAttention等)持续跟进迭代